A short summary of impactful papers in image generation

This is a short list of papers on image generation that I compiled mostly for myself, but figured I might as well put it into a public place.
There are loads of papers being published every day, so this list is very much non-exhaustive. I try to pick the papers with the biggest practical use for people who try experiment with image generation models themselves.
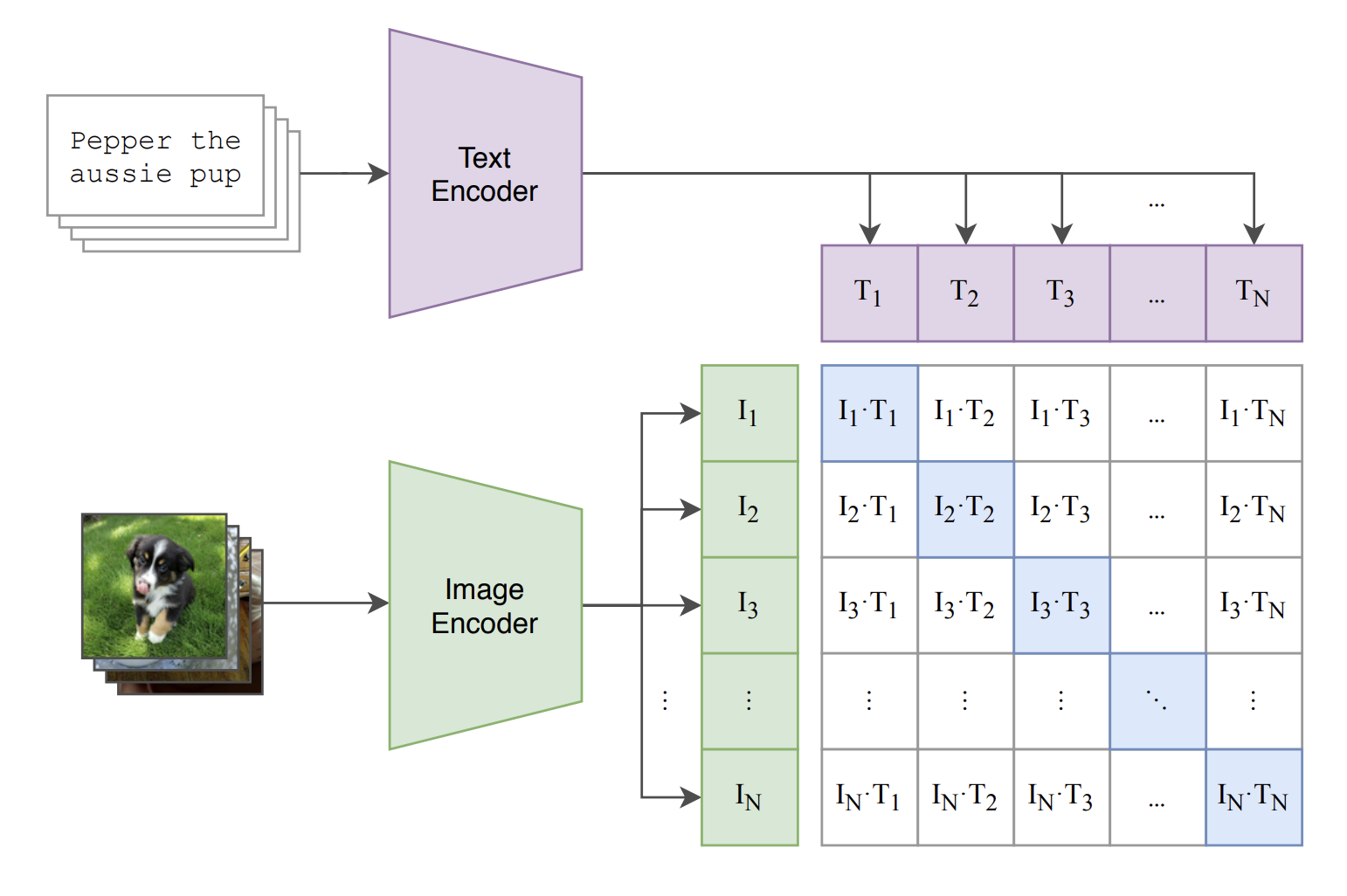
CLIP (Learning Transferable Visual Models From Natural Language Supervision)
The authors scrape 400 million <text, image> pairs from the internet. They then train a text encoder and image encoder to maximise the cosine similarity of each actual <text, image> pair while minimising the cosine similarity between <text, image> pairs that don’t belong together. They use a transformer as text encoder and experiment with both a ResNet and a Vision Transformer as image encoder.
The resulting model can be used for image retrieval given text or images, zero-shot or few-shot image classification or as a guidance for text-to-image models (see DALL-E, Stable Diffusion).
Paper: https://arxiv.org/pdf/2103.00020.pdf
GitHub: https://github.com/openai/CLIP
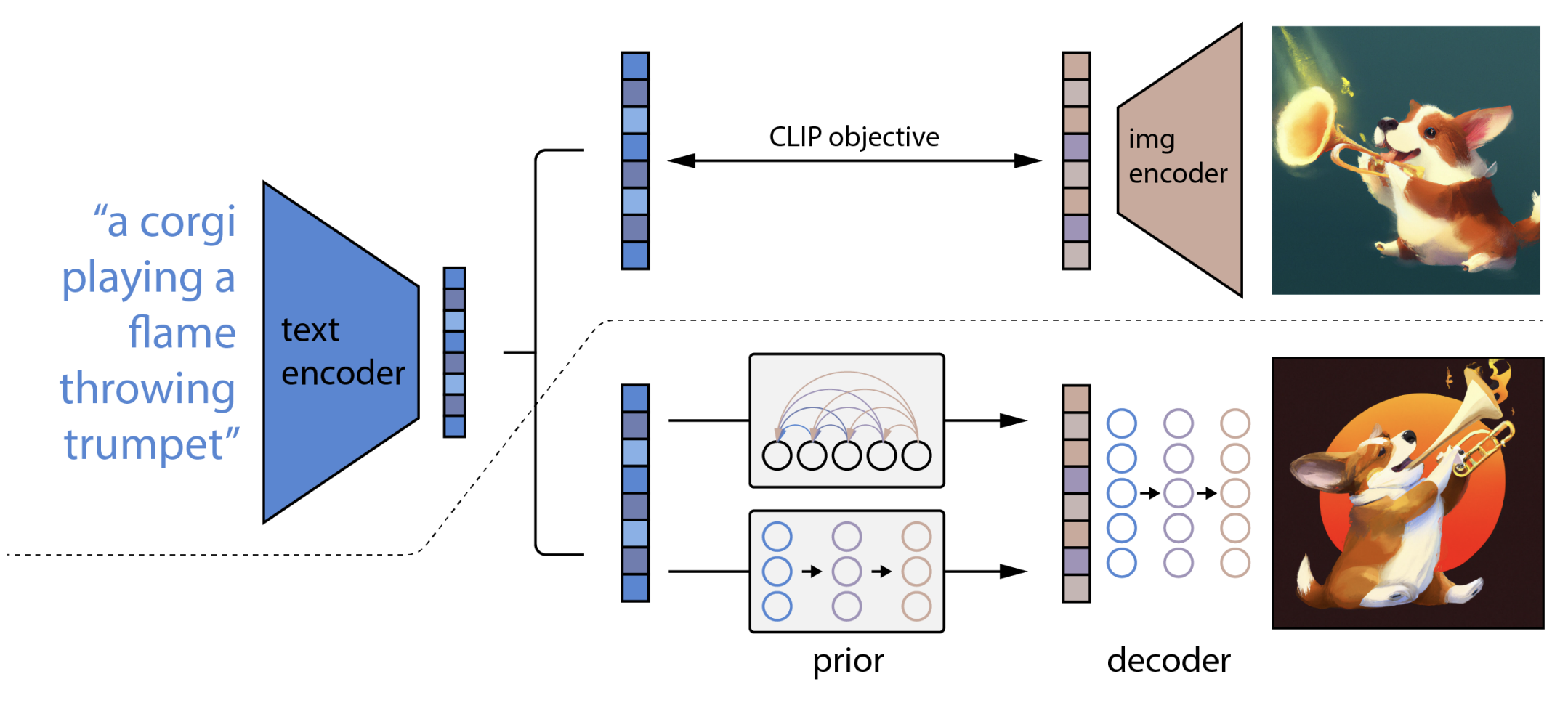
DALL-E 2 (Hierarchical Text-Conditional Image Generation with CLIP Latents)
The authors use a dataset of <text, image> pairs to create a text-to-image model, by encoding the text using the CLIP text encoder, then using a “prior” model to generate a CLIP image embedding from the text embedding and then finally feed the image embedding together with the text into a decoder model that generates the final image. For the prior model, the authors experiment with both an autoregressive transformer model and a diffusion model. For the transformer model, they dimensionality-reduce and discretise the image embeddings to get discrete tokens. The decoder is a diffusion model conditioned on the image embedding and the text caption.
DALL-E 2 can generate variations of images by encoding an image using the CLIP image encoder and then feeding that image through the DALL-E 2 image decoder.
Paper: https://cdn.openai.com/papers/dall-e-2.pdf
GitHub: https://github.com/lucidrains/DALLE2-pytorch (unofficial implementation)
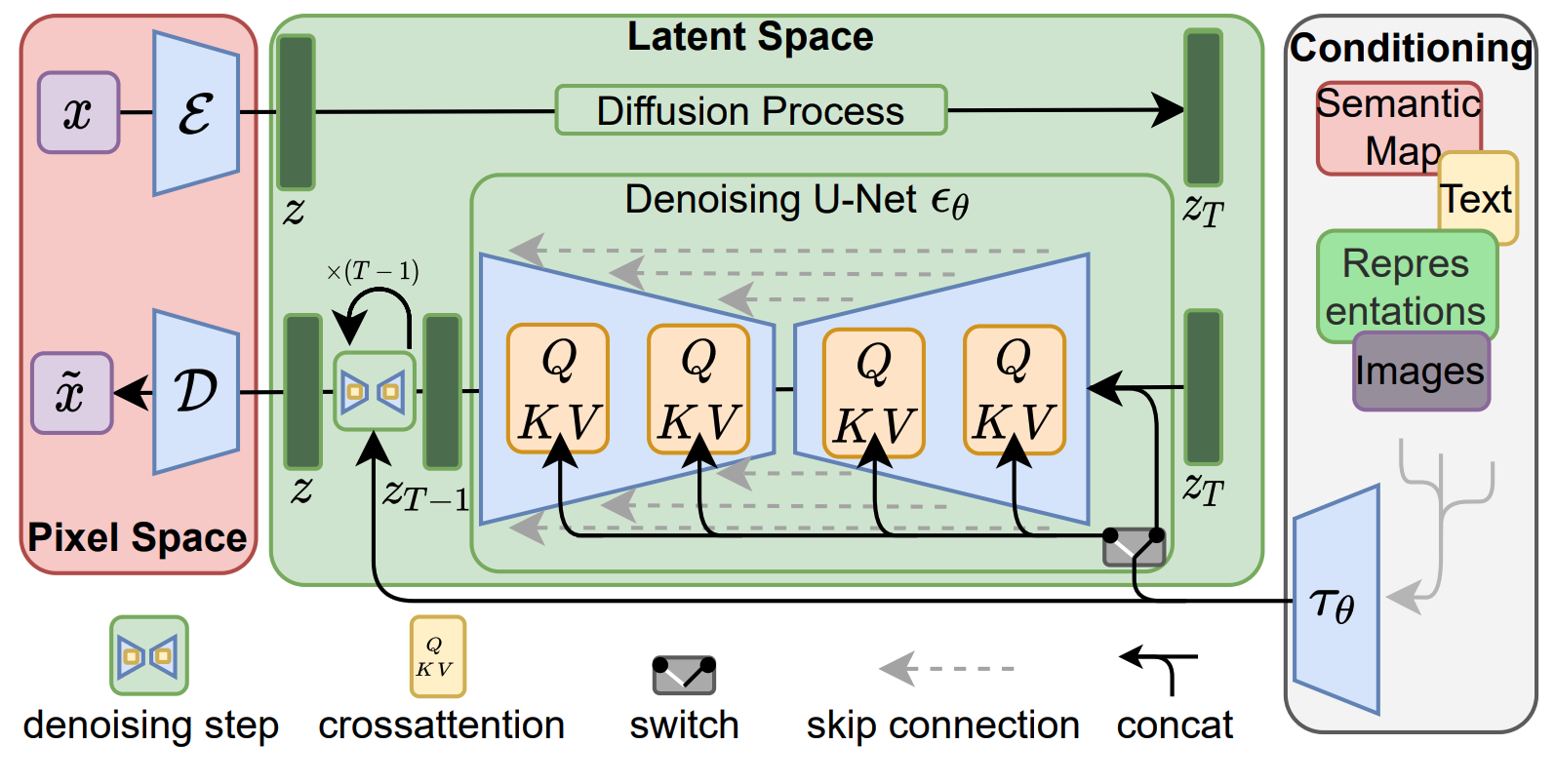
Stable Diffusion (High-Resolution Image Synthesis with Latent Diffusion Models)
The central idea in Stable Diffusion is to perform the diffusion process in a compressed latent space instead of the more expensive pixel space. To do that, the authors train a denoising autoencoder to encode images into a latent space with two spatial dimensions. A UNet is trained to denoise images in that latent space. The UNet can be conditioned using cross attention. To condition the model on text, the authors use a CLIP text encoder to generate text embeddings to feed into the cross attention. The model is trained on the LAION-400m dataset, i.e. 400 million <image, text> pairs.
Stable Diffusion was the first open source image generation model that was practically useful while running on consumer hardware.
Paper: https://arxiv.org/pdf/2112.10752.pdf
GitHub: https://github.com/CompVis/stable-diffusion
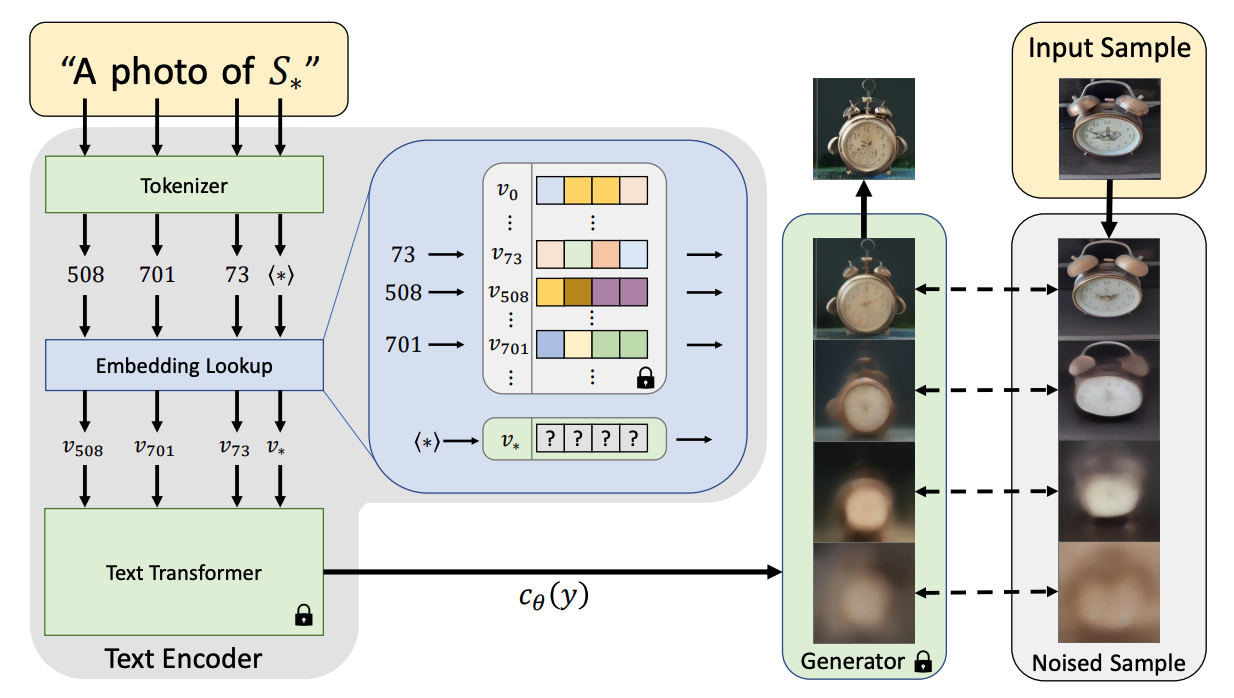
Textual Inversion (An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion)
Textual inversion adds a new token to represent a specific concept (e.g. a person) or style (e.g. Picasso painting). The embedding of that token is trained through a frozen stable diffusion model to on a small number of images of that concept, using prompts like “A photo of S” where S is the new token.
Paper: https://arxiv.org/abs/2208.01618
GitHub: https://github.com/rinongal/textual_inversion
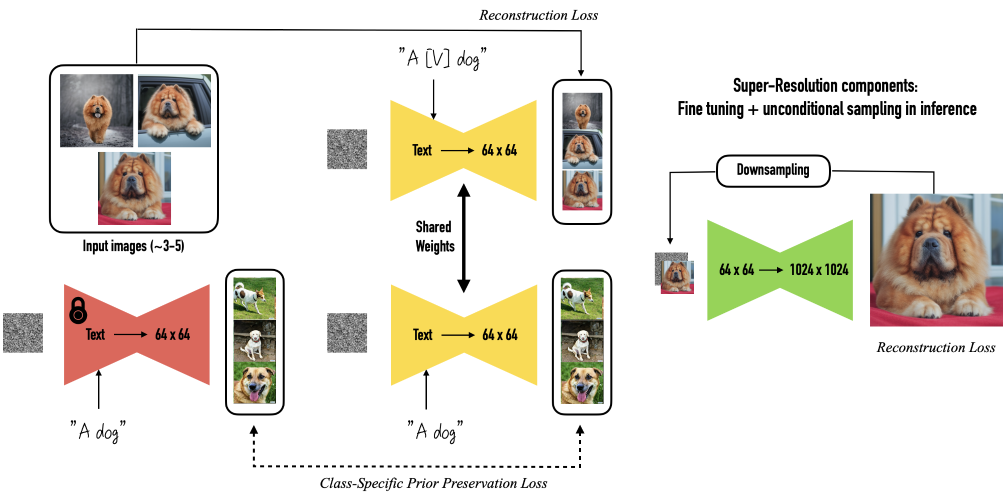
DreamBooth
Fine-tunes a diffusion model to add a specific subject to the model’s latent space which can then be rendered in various contexts while preserving the subject’s identity. The method requires 3-5 images of the subject and the class to which the subject belongs (e.g. dog or person). A rare token (e.g. [V]) is used as identifier for that subject, such that “A photo of a dog” would generate a picture of any dog, but “A photo of [V] dog” would generate the specific dog that the model was fine-tuned on. To avoid language drift and encourage output diversity (i.e. avoid overfitting on the few examples used for fine-tuning), a prior-preservation term is added to the loss function. This term makes sure the model retains it’s behaviour for prompts that don’t include the subject identifier by comparing the fine-tuned output to images sampled from the initial model for generic prompts of the subject’s class.
Paper: https://arxiv.org/pdf/2208.12242.pdf
GitHub: https://github.com/google/dreambooth
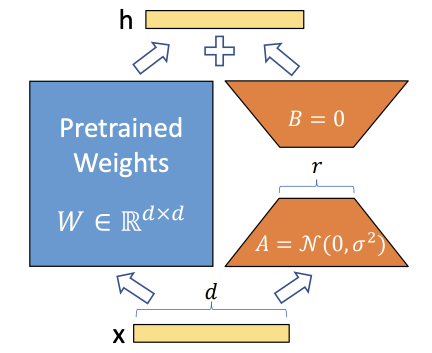
LoRA
Originally proposed for LLMs, LoRA is a method to fine-tune models by freezing the base model and only train a residual of the weight matrices, approximated by two low rank matrices. This makes LoRA training fast and the resulting fine-tuned models small (as we only store weights for the low rank matrices, not fine-tuned weights for the whole base model). In the context of image generation, LoRA is often applied to the cross-attention layers in Stable Diffusion that condition the image generation on the text content.
Paper: https://arxiv.org/pdf/2106.09685.pdf
GitHub: https://github.com/cloneofsimo/lora
Prompt-to-Prompt
A technique to edit images generated by diffusion models by editing the text prompt only without a mask to localise edits. We can swap out, add, remove or change the weighting of words in the prompt. To keep the parts of the image that should not be affected by the prompt edits consistent, the authors use the cross attention maps to constrain the image generation. To swap or add words, use the original cross attention maps for all unchanged words. To change the weighting of words in the prompt, change the weighting of cross attention maps. To change the style of an image while preserving its contents, keep the cross attention maps. To avoid over constraining the output image, only inject the original attention maps up to a diffusion step when generating the edited image, as some edits will need to change the geometry of the otherwise unchanged objects in the image. 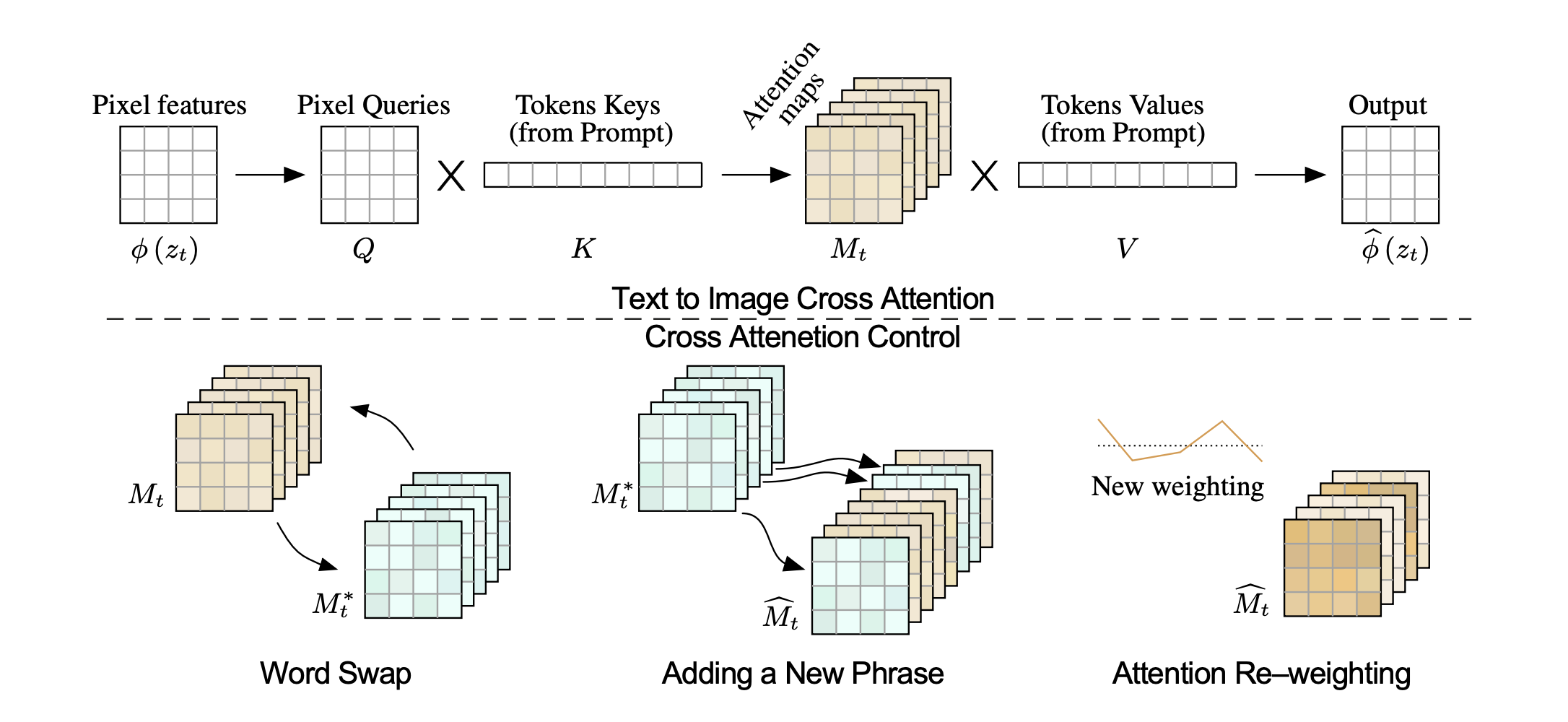
Paper: https://arxiv.org/pdf/2208.01626
GitHub: https://github.com/google/prompt-to-prompt
InstructPix2Pix
Given a list of image captions, use GPT-3 to generate an edit instruction and an edited caption for each original caption. Then use Stable Diffusion and Prompt2Prompt to generate two images for each original caption, one using the original caption and one using the edited caption. That results in a dataset of image pairs together with an editing instruction to get from one image to the other. Train an image-to-image model on this dataset to get a model that can follow image editing instructions on arbitrary images.

Paper: https://arxiv.org/abs/2211.09800
GitHub: https://github.com/timothybrooks/instruct-pix2pix
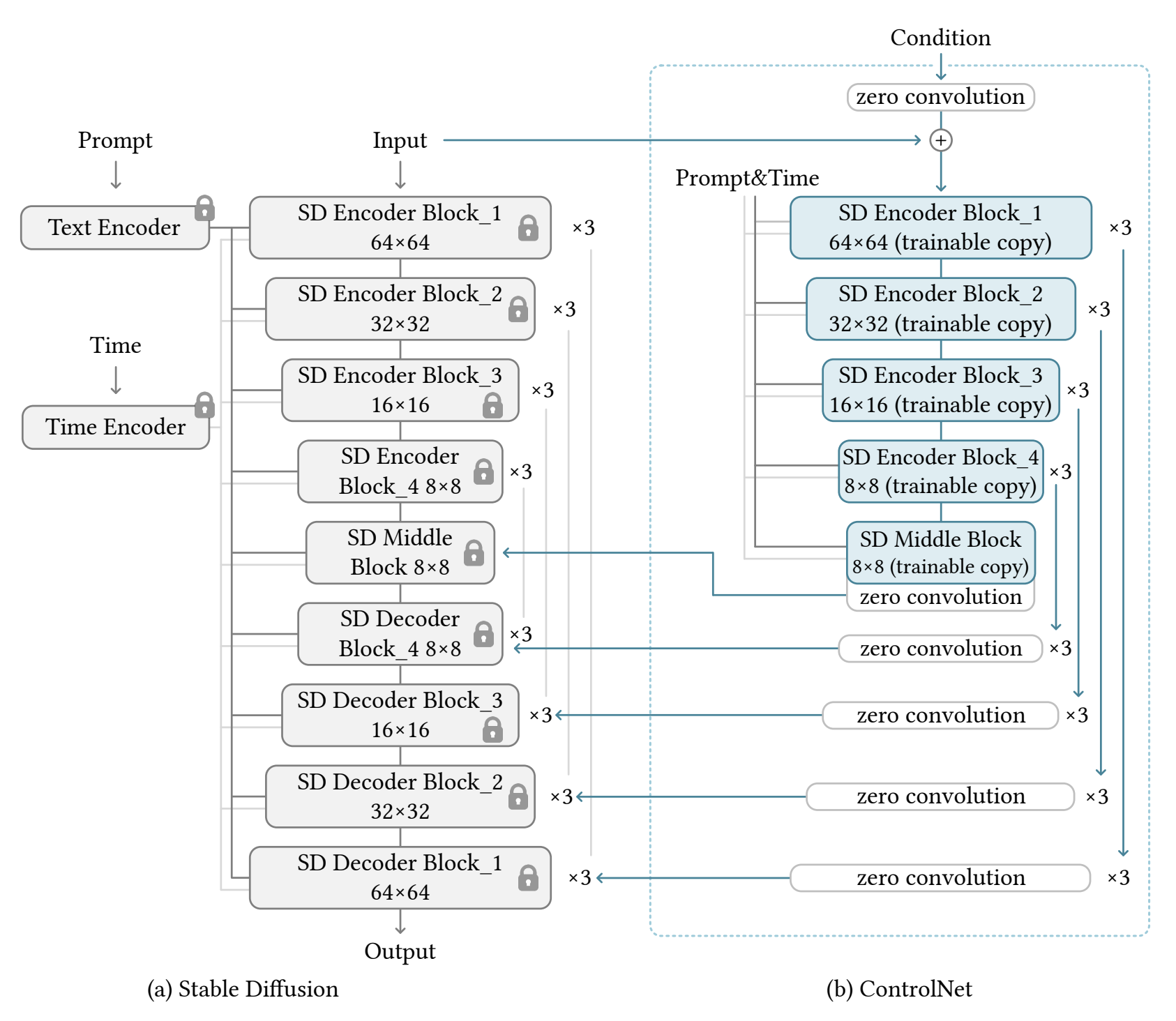
ControlNet
Conditions a Stable Diffusion model on additional inputs (e.g. edge maps, segmentation maps) by freezing the SD model, adding a trainable copy of the SD model and adding feature maps from the trainable model to the feature maps from the frozen model. Augmenting the frozen model with an additional trainable model ensures the resulting model doesn’t “forget” concepts when trained on smaller datasets.
An ablation study (https://github.com/lllyasviel/ControlNet/discussions/188) shows that the deep encoder (aka. trainable copy of the SD model) can be replaced by a lighter encoder model or even an MLP trained from scratch without losing much performance on text-to-image generation. The deep encoder model does significantly outperform both alternatives when no text prompt is given (i.e. the image is only conditioned on e.g. edge maps).
Paper: https://arxiv.org/pdf/2302.05543.pdf
GitHub: https://github.com/lllyasviel/ControlNet